|
business relationship clusteringveryard projects > business relationship management > business relationship clustering |
|
|
|
|
| This document describes a business relationship clustering
algorithm that is designed to support judgements about business relationships,
including strategic planning.
We construct an agent-responsiblity model, and perform an affinity clustering to determing suitable clusters of responsibilities. These clusters are then used to identify desired business relationships, and to support negotiation with possible business partners. |
Clustering
|
 Clustering
|
![]()
Clustering is essentially a topological exercise. Topology can be thought of as the mathematics of scope, defining the boundaries between outside and inside. In general, there may be a complex structure of such boundaries, both nested and overlapping.
A clustering exercise takes a set of entities and positions them in a topological space, consisting of a set of neighbourhoods. These neighbourhoods may then be used to define the scope of projects, systems or organizations. A clustering exercise is successful (relative to a given purpose) if these neighbourhoods prove stable, efficient and flexible.
Two forms of clustering are commonly identified. Interaction clustering groups entities into neighbourhoods according to the quantity and importance of the interactions between them. This is particularly suitable for software engineering structures, where the success of clustering is often measured in terms of maximum cohesion and minimum coupling. Affinity clustering groups entities into neighbourhoods according to the defined similaries (or lack of dissimilarities) between them. This is particularly suitable for many organization and management structures, where the success of clustering can largely (although never entirely) be gauged in terms of the economies of scale and scope.
Business relationship clustering is an example of affinity clustering.
Other examples of clustering
Clustering is commonly found in financial and medical applications. For a general description of clustering algorithms in IT, see [Veryard 1994].
Clustering algorithms for software design purposes are included in Cool:Gen, formerly known as IEF or Composer.
Early versions of the IEF contained an affinity clustering algorithm. An interaction clustering algorithm has been developed, which has been incorporated into more recent versions of IEF and Composer.
Besides COOL:Gen, there are a few other tools that contain clustering algorithms. These include Netmap and Data Mariner. Netmap uses interaction clustering on communication patterns to identify the actual groupings within an organization (which often differ significantly from the formal groupings). Data Mariner uses conventional statistical techniques for exploring data, combined with some artificial intelligence methods for extracting rules from it.
This section describes the context of business relationship clustering.
A business planner is typically faced with a complex and dynamic situation, containing a large number of interconnecting roles. This situation may be represented in the form of a business relationship model, which identifies the responsibilities for each role, as well as the delegation structures between them.
Within this situation, the planner is required to make a number of judgements. These judgements may include:
This section describes the purpose of business relationship clustering. Given the existence of a business relationship model, and a planner faced with a set of planning imperatives, how does business relationship clustering help with the planning judgements?
In the management literature, business planning is increasing recognized as an exercise in creating business networks and alliances.
The required judgements can be formulated in topological terms, for example:
Responsibility Modelling
Business Relationship Modelling relies on identifying agents and their responsibilities to one another for a set of desired states.
A responsibility is a three-part relation involving two agents and a state. The first agent is responsible to the second agent for achieving or maintaining the given state. For example, the Logistics Officer (agent 1) is responsible to the Leadership Team (agent 2) for maintaining conformance to US Export Policy (desired state).
The algorithm starts with three sets:
Algorithm - Calculation
| Step 1 | For each agent role AR0, the responsibility involvement set of AR0 is defined as the set of responsibility triples <ARi, ARj, Sk> where AR0 = ARi or AR0 = ARj. This is known as RIS(AR0) |
| Step 2 | For each pair of responsibility triples R1 = <A,B,S> and R2 = <C,D,T>, where A,B,C and D are agent roles, and S and T are desired states, the responsibility affinity F(R1,R2) between them is defined according to a look-up table. |
| Step 3 | For each pair of agent roles AR1 =AR2, the agent role affinity between them is calculated as the average responsibility affinity of each member of RIS(AR1) with each member of RIS(AR2). |
| Step 4 | Select the lowest number F0 that partitions the set {AR1, , ARn} into discrete neighbourhoods. |
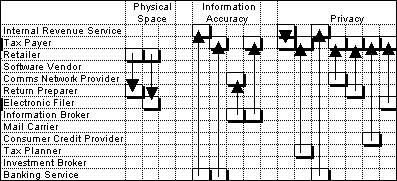
This example is taken from a paper by Kambil and Short, and concerns the introduction of electronic tax filing by the IRS. Kambil and Short use what they call a roles-linkage perspective on this example. We believe that the business relationship modelling approach provides a significantly better insight into the structural opportunities.
The Kambil and Short paper identifies
13 agents. We have supplemented their analysis by speculatively identifying
6 states, and mapping the responsibilities between agents and states as
in the following matrix.
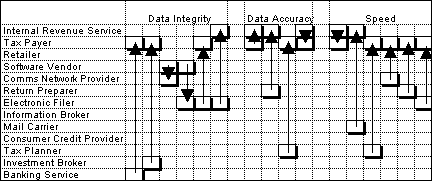
|
Performing the clustering algorithm
against this agent-responsibility matrix results in the following six clusters:
| Comms Network Provider
Electronic Filer Return Preparer |
Retailer
Software Vendor Information Broker |
| Tax Payer
IRS |
Mail Carrier
Consumer Credit Provider |
| Tax Planner | Investment
Broker
Banking Services |
Comment
The algorithm described here is unique in three ways:
Next steps for exploiting the algorithm are
Ajit Kambil & James E. Short, Electronic Integration and Business Network Redesign: A roles-linkage perspective Journal of Management Information Systems 10 (4) Spring 1994 pp 59-83
Texas Instruments, Scoping in Information Engineering with Interaction Scoping Tool, Version 3.05 (10 March 1992)
Richard Veryard, Information Coordination: The Management of Information Models, Systems and Organizations (Hemel Hempstead: Prentice Hall, 1994)
Acknowledgements
Drafted by Richard Veryard, April 1995, with the aid of Sally Jack and Ian Macdonald. Updated July 1995, to include worked example and literature search.
![]()
Contact Details

Veryard Projects is a technology consultancy, based in London. |
We welcome enquiries from those wishing to use the algorithm |
Algorithm originally developed April-July 1995.
Description updated June 7th, 1999.
Copyright © 1995, 1999 Veryard Projects
http://www.veryard.com/sebpc/brcluster.htm