
Saturday 5 September 2015
A web page about one possible way of encoding localizable sentences: each localizable sentence encoded using a base character followed by a sequence of tag characters, the same base character for each encoded localizable sentence.
Here are some transcripts. They are repeated here so that they will become archived in the British Library.
http://www.unicode.org/mail-arch/unicode-ml/y2015-m05/0196.html
Tag characters and localizable sentence technology (from Tag characters)
I refer to the following documents, the first about localizable sentences and the second about, amongst other matters, applying tag characters using a new encoding format.
http://www.unicode.org/L2/L2013/13079-loc-sentance.pdf
http://www.unicode.org/L2/L2015/15145r-add-regional-ind.pdf
Starting from the idea of the markup bubble from the first document and applying the tag method and the ISO standard document method from the second document, there arises the following possibility for the future for localizable sentence technology.
A single character would be added into Unicode, the name of the character being
LOCALIZABLE SENTENCE BASE CHARACTER
and then the plain text encoding of a particular localizable sentence would be defined as being expressed as the LOCALIZABLE SENTENCE BASE CHARACTER character followed by the code for the localizable sentence specified in the ISO [number] document, the code being expressed using tag characters.
Please find attached a design for the glyph for the LOCALIZABLE SENTENCE BASE CHARACTER character.
I designed the glyph by adapting and then combining the designs for localizable sentence markup bubble brackets from the first of the two documents referenced earlier in this text.
Each localizable sentence, carefully written so as to avoid in use any reliance as to meaning on any sentence previously used in the same document, would have a meaning expressed in words and possibly also have a glyph: more commonly used localizable sentences each having a glyph yet not all other localizable sentences necessarily having a glyph, though some could have a glyph, as desired.
William Overington
22 May 2015
http://unicode.org/mail-arch/unicode-ml/y2015-m06/0204.html
Summer 2015 Localizable Sentence Concept Assessment Experiment
Please use the Base Character followed by Tags concept to express two localizable sentences so as to facilitate transmission and reception of a message through the language barrier.
However, only plane 0 Private Use Area characters are used for base character and tags.
This is so as to use only Private Use Area characters because the Base Character followed by Tags concept applied to localizable sentences has not at this time been officially accepted, in fact at this time not having been put forward formally for consideration regarding official acceptance either.
Also, an all plane 0 initial concept proving may possibly be somewhat easier in practice than a plane 15 concept proving.
U+EFFF EXPERIMENTAL LOCALIZABLE SENTENCE BASE CHARACTER
U+EE20 .. U+EE7E EXPERIMENTAL TAG CHARACTERS
The experimental tag characters are the same meanings as, respectively, the tag characters U+E0020 .. U+E007E of regular Unicode.
The experiment needs to provide for at least the following.
----
Enter each sentence from a menu where the sentence is listed in English.
Selecting from the menu to cause the Private Use Area codes for the sentence to be included in a message, with the English text not appearing in the message.
Transmitting and receiving the message.
Decoding the message to produce the message displayed localized into Swedish.
----
The sentences are as follows, shown in English, then the sequence of code point descriptions, then shown in Swedish.
----
Good day.
U+EFFF U+EE31 U+EE30 U+EE30 U+EE30 U+EE31
God dag!
----
Best regards,
U+EFFF U+EE31 U+EE30 U+EE30 U+EE31 U+EE34
V�nliga h�lsningar,
----
The translations are from the following post by Magnus Bodin.
http://www.unicode.org/mail-arch/unicode-ml/y2009-m04/0231.html
----
Just in case the accented characters are displayed wrongly in either the mailing list email or in the archive, please know that there are only two accented characters and that the two accented characters are both the same and are as follows.
U+00E4 LATIN SMALL LETTER A WITH DIAERESIS
The character is listed in the following document.
http://www.unicode.org/charts/PDF/U0080.pdf
----
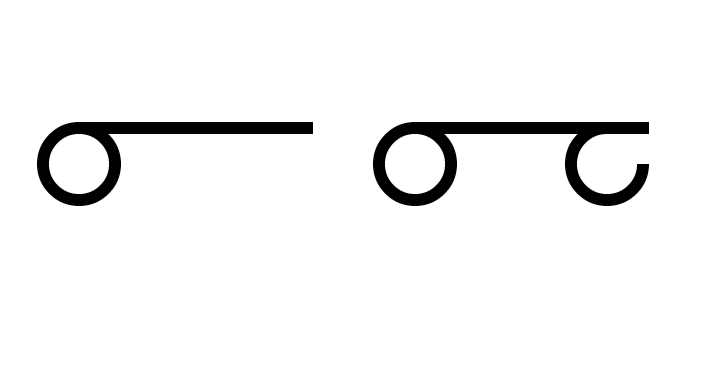
Glyphs for the two localizable sentences are not necessary for this experiment, but should they be of interest and useful, please find attached an image of the two glyphs, the less complex one, at the left, being for Good day.
----
The following post is mentioned in case it is helpful.
http://www.unicode.org/mail-arch/unicode-ml/y2015-m05/0196.html
----
As it happens I do not personally at present have the knowledge, skills and facilities to carry out the experiment and prove the concept myself.
Alas, there is no prize for participating, yet it is not a competition either.
Participation could however potentially have far reaching beneficial advantages for the future of communication through the language barrier.
William Overington
24 June 2015
http://forum.high-logic.com/viewtopic.php?p=26363#p26363
It is now 9:29 am United Kingdom time as I write.
This morning I have tried making a font for the first time since I got my new laptop computer, running Windows 8, following the break down of the Windows xp computer that had served well for many years.
This went very well.
Here are the notes that I made as I went along.
====
Saturday 5 September 2015
This is the producing of a font relating to the following Unicode mailing list forum post.
http://unicode.org/mail-arch/unicode-ml/y2015-m06/0204.html
8:11 am
Experimental font LOCSE701.TTF
Start by opening LOCSE034.TTF
Save as a new project LOCSE701
Except for the two localizable sentence markup bubble brackets and the associated digits, remove the Private Use Area glyphs as this is just to be a minimum font for the purpose.
Rename the font as Localizable Sentences 701 and set export names as LOCSE701
Insert code points for U+EE30..U+EE39 and for U+EFFF.
The code for the Insert characters facility is
$EE30-$EE39,$EFFF
Copy just the glyphs of the digits still in the Private Use Area to U+EE30..U+EE39.
Delete the originals.
Adapt and combine the glyphs of the two localizable sentence markup bubble brackets to produce a glyph for the base character.
Delete the originals.
The glyphs for the base character and the digits will only show when there is no automated localization in action.
Now, as these are experimental glyphs in a Private Use Area, add an E below the base line so that if the base glyph is ever encoded into regular Unicode there will be no confusion.
Validate the font.
Test the font using the preview panel.
Export the font.
8:56 am
----
8:59 am
Change version string to show the date as I like it, day month year style.
Export the font.
Close the project file.
9:06 am.
Open the font.
Install the font.
Test the font using PagePlus X7.
====
Here are graphics exported from PagePlus X7.


Here is the font.
William Overington
5 September 2015
http://forum.high-logic.com/viewtopic.php?p=26364#p26364
Readers who would like to try the font yet who do not have any software that has an Insert Symbol facility may find the following useful.
I have typeset the eleven characters from the plane 0 Private Use Area within Serif PagePlus X7 and I have produced eleven lines of text, each of which consists of a note of the Unicode code point that I have used for the character together with the character itself between two = signs.
This use of the = signs is because in some browsers the characters may be shown as a black rectangle, or as a black square with the hexadecimal code within it, or just show nothing, just leaving what looks like a space.
The = signs will hopefully be useful guides if, for example, trying to copy from a web page and paste into WordPad.
To display the glyphs in WordPad the font would need to be installed, perhaps only temporarily, and then the characters formatted using the font. It is sometimes necessary to only open the application program once the font has been installed.
Anyway, in the hope that they will be useful, here are the eleven lines of text.
U+EE30==
U+EE31==
U+EE32==
U+EE33==
U+EE34==
U+EE35==
U+EE36==
U+EE37==
U+EE38==
U+EE39==
U+EFFF==
If you have any questions, please feel free to ask.
William