
modelling rules
veryard projects > modelling > rule modelling
|
modelling rulesveryard projects > modelling > rule modelling |
|
| we offer | scope | available material | links |
| education, training and skills
transfer
model reviews information and advice on methods and tools supporting materials - including patterns |
Business rule modelling provides a view of the
rules, policies, regulations and other constraints imposed on the business.
This includes structural constraints as well as process/sequence constraints,
and gives us (among other things) a view on workflow,
workload and work control.
We use a general notion of rule, that includes related concepts such as constraint. This notion can apply at any level: to a method/operation, to a whole component, or to a whole system. This means we need ways of understanding rules to allow for composition and decomposition. In particular, we may want to encapsulate rules - designing a set of software components each scoped around a single well-formulated rule - and then reason about the global behaviour of the assembled systems. |
Rule Diagram
What is rule modelling good for? Models and Monsters - The Exception "Proves" the Rule Declarative and Procedural Specification (What not How) |
 |
Rule Model Diagramveryard projects > modelling > rule modelling > diagram |
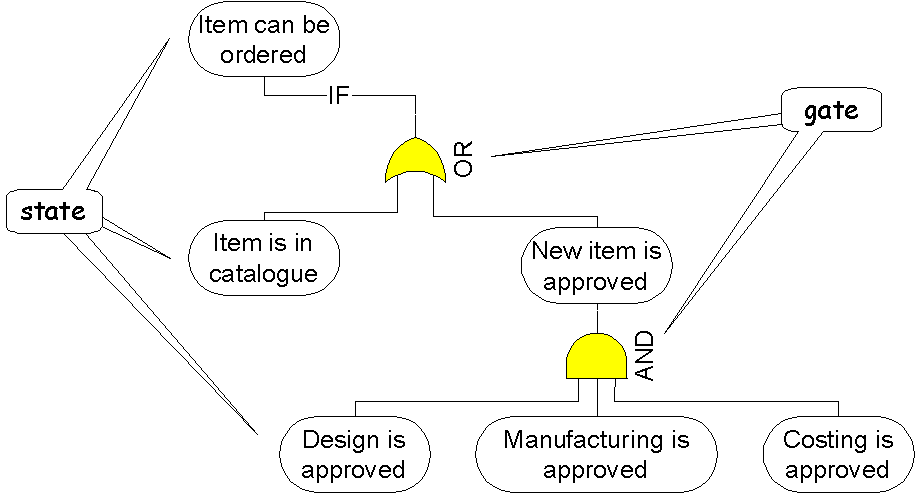
![]()
|
|
||
| Business
Understanding |
Business rule modelling provides a view of the rules, policies, regulations and other constraints imposed on the business. This includes structural constraints as well as process/sequence constraints, and gives us (among other things) a view on workflow, workload and work control. | |
| Flexible
Design |
If system design is based on a rule architecture, then we should expect
the following benefits:
|
|
| Upward
Rationalization |
Improve the structure and behaviour of systems by introducing or strengthening
useful rules.
|
|
| Downward
Rationalization |
Improve the structure and behaviour of systems by eliminating bad or
redundant rules.
|
|
| System
Understanding |
Make informed judgements about system structure and behaviour. Reason intelligently and reliably about the effects of ruleset changes. | |
| System
Inference |
Business rule modelling can be carried out on a blackbox system - simply by observing the (external) behaviour of a system or organization, we can infer the rules by which it is governed. This means that it is useful as a way of reasoning about the potential behaviour of customers and competitors under various conditions. It also means we can reason about the emergent properties of complex systems without knowing the detailed structures and mechanisms of the components and services from which the systems are assembled. | |
|
|
|
||||||||
So if rule modelling is such a good thing, why isn't it more widely practised? |
We believe that tools will go some way to address these concerns. However, there is currently a shortage of good modelling tools in this area. We deplore this situation, and we are seeking to redress it. |
![]()
| Modelling | Given a system (organization, human, computer or hybrid), produce a
set of rules that explains the behaviour of the system.
Note: we can carry out this modelling even when we have no access to the internal structures and mechanisms of the system - the blackbox scenario. |
|
| Testing | Given a system and a set of rules, test whether the behaviour of the system (regarded as a blackbox) conforms to the rules. | |
| Requirements | Specify a desired behaviour pattern, or a desired change to an existing behaviour pattern, as a set of rules. | |
| Implementation | Design something to implement a ruleset or ruleset change. (This may be a software artefact, a work practice, or a hybrid sociotechnical system.) | |
| Verification | Predict the interaction between multiple rulesets.
|
|
| Exploration | Analysing a system and its rules to find improvement opportunities.
|
![]()
|
Flexibility as the Absence of Rulesveryard projects > modelling > rule modelling > flexibility |
For example, a bespoke application program may be written on the assumption that all amounts of money are in US dollars, and all dates are in US format. These can be regarded as rules embedded in the program, which constrain the possible use of the program in Europe or elsewhere. In contrast, an application package may be written without these rules, allowing for any currency and a wide range of date formats.
It is often more difficult to spot the absence of rules than the presence of rules.
When considering the acqusition and implementation of large application packages such as SAP, PeopleSoft and Baan, you need to take a view both on the constraints (rules) built into the package, but also the degrees of freedom (absence of rules).
For every degree of freedom, for every absent rule, there is the possibility
of a choice. This choice may be exercised in many different ways - perhaps
at design time by the implementors, perhaps at run-time by the users, or
perhaps by a separate software component containing a decision algorithm.
| The Nature and Nurture of Flexibility |
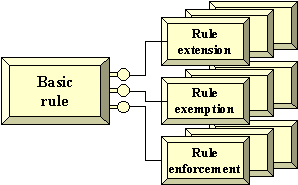 |
Basic Rule - on this road, maximum permitted speed = 90 kph
Extension - private aeroplane crash-lands on road, triggering speed camera - does this rule apply in this case? Exemption / Exception - police, doctors, priests (subject to role) Enforcement - speed camera, fine |
We often want to add or change extensions, exemptions and enforcement rules.
And we often want to analyse the aggregate or ecological effect of a subsidiary rule. For example, consider the following rule enforcement exemption (don't pursue foreign cars).

What are the consequences of this rule enforcement exemption (don't
pursue foreign cars)?
|
|
Among other things, this analysis indicates that a rule enforcement
exemption should not always be reduced to a rule exemption.
![]()
Many structured methods for relational database (such as Information Engineering) allow you to have derived attributes. I thought it would be good to have derived entity types and relationships as well. I published a paper about this in Information and Software Technology over ten years ago (when Information Engineering was still fashionable), and this paper became Chapter 5 of my book on Information Modelling.
Given that relational databases with raw SQL supported a wide range of derived tables (although the performance wasn't always brilliant), I always thought it was a pity that some CASE tools and structured methods didn't take advantage of this.
My main concern then was that the rules should remain the same even when the data change. (I was always sceptical of the presumption that data changed less frequently than business process.)
This approach has to be carefully qualified. I came across the following example recently in a supermarket chain. In the old system, the stock figures presented to the store manager in the morning were based on yesterday's figures, with an adjustment for any expected overnight deliveries. But of course sometimes the expected overnight deliveries didn't turn up, and so the figures would be wrong. In the new system, overnight deliveries would be recorded into the database immediately. Stock reports would be printed off at midnight ready for the following morning, and would accurately include all deliveries made before midnight. So therefore the store manager would have more accurate stock data. Or would he?
What about deliveries scheduled after midnight? What about deliveries arriving after midnight (especially those scheduled for delivery before midnight)? Interviewing the IT project manager, I got a strong impression that these questions had not been properly thought through.
Of course the midnight printout process is a naff one, and we can think of various ways of fixing it. What interests me most in the midnight printout example, is the nature of the error in thinking that led to this naff process. This supermarket chain was spending a large amount of money on implementing this naff process - not just the IT development and equipment costs, but the change management costs as well. As far as I could tell, there was a genuinely held belief that this was worth doing, because it made the data more accurate. And there was a cost-benefit argument supporting this - I didn't ever see it, but I know it existed. My hunch is that there was a particular kind of data-oriented thinking, together with a particular notion of data accuracy, which led to this error.
Among other things, I'm looking for a good way of reasoning about such situations. I'm not convinced that a data-oriented approach forces analysts to ask all the right questions, in a systematic way. I believe that an explicit rule analysis would have helped the analysts avoid this naff process.
Note that in this case, the condition is determinate. Either the delivery schedule is before midnight or it's not. We could therefore represent midnight as a state transition, if we wanted to. But sometimes we use conditions that cannot be determined in advance. This is especially true in open distributed systems.
For example, an application needs to carry out an Internet search. We may put out multiple enquiries in parallel, and respond to whatever responses we get. Thus SEARCH-RESULT = (YAHOO-SEARCH and LYCOS-SEARCH and ALTAVISTA-SEARCH and ... and ...) On a particular occasion, some of the search engines may not yield a response within a specified time.
But we don't know this in advance. This is why we cannot code this as SEARCH-RESULT = (IF yahoo is quick today THEN YAHOO-SEARCH else LYCOS-SEARCH.)
![]()
![]()
| top |  |
|
|
Copyright © 1999-2001 Veryard Projects Ltd http://www.veryard.com/kmoi/rulemodelling.htm |