
|
data mapping and transformation |
|
Why do we have several data models?
If we can establish data mappings from one model to another, then we can translate data for example to perform ETL from one data store to another. It also enables us to transform stuff that depends on data structure in other words, helping us reuse stuff across multiple ontologies. |
 |
The Raw and the Cookedveryard projects > information management > data mapping and transformation > raw and cooked |
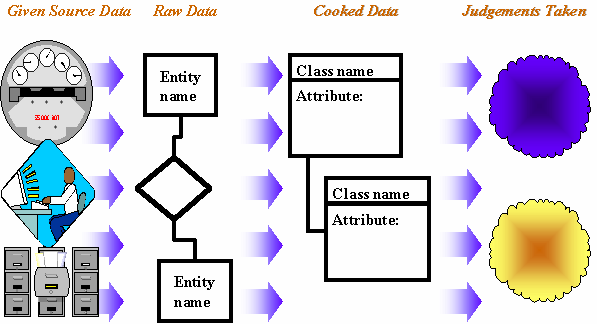
Simplistic data modelling assumes that there is a clear distinction between atomic data and derived (molecular) data but it doesnt work out as clearly as this in practice, and this issue may have sweeping implications for system architecture and design.
The starting point for us is often the transformation between the raw and the cooked. The raw refers to detailed records of business transactions and operations, as well as detailed records of market intelligence. The cooked refers to consolidated reports of business results and competitive performance.
One of the differences between the raw and the cooked is the level of granularity. Usually (but not always) the raw is finer (smaller grained) than the cooked. Another difference is the level of complexity. The cooked data may be modelled as more complex data objects, while the raw data may be modelled as apparently more simple data objects.
In my 1992 book, I discussed how such transformations could be expressed using an extension to traditional data modelling notations. Object modelling notations can sometimes express these transformations more elegantly.
A clustering algorithm can be used to join up simple data objects (raw data) into complex data objects (cooked data). This is something addressed inadequately by data warehousing methodologies.
Privacy and confidentiality requirements sometimes place restrictions on the dissemination of raw data (in which the subjects can be identified), meaning that only cooked data may be available. (Clever transformation can sometimes allow identity to be reconstructed - often inaccurately, but good enough for some purposes. Inference Control is used to prevent such breaches or leaks.)
But if we focus on the transformation between the raw and the cooked, between simple data objects and the complex data objects, we may overlook the other two transformations depicted above. The data architecture needs to call two things into question: the reliability of the source data and the strategic opportunities opened up by the information. These both demand a level of data reflexivity (data about data, data about itself, sometimes called metadata).
Finally, we should not overlook the possibility
of linkage between the source data and the business strategy. The availability
and reliability of source data is itself dependent on the strategic alliances
formed by the organization. Furthermore, any organization is vulnerable
to being fed false information by its competitors, which may tempt it into
poor business judgements. Data means that which is given, but by whom,
to whom, and for what purpose?
| Give and Take of Information
Grain and Granularity Privacy and Granularity Information Leakage |
| top |  |
|
Copyright © 2001-3 Veryard Projects Ltd http://www.veryard.com/infomgt/datamapping.htm |