Issue 1, January 1984 - Speech Synthesis
| Home | Contents | KwikPik |
| "sp(ee)ki(ng) of spe(ck)t(rr)ums" | Adding speech to your Spectrum opens up a whole new dimension for experimentation. No longer do games programs have to be silent events with the occasional computer-generated snap, crackle and buzz. Mark Anson gives an introductory guide to speech analysis on home computers. | ||
|---|---|---|---|
|
Human speech is essentially a subset of
sound synthesis in its broadest sense;
that is, if you have control over pitch,
waveform and amplitude then it's possible to synthesise any sound, including
speech. In practice, total sonic shapers
are very sophisticated microcomputer
systems in their own right, and hardly
add-ons to interest the home computer
enthusiast. The Spectrum user is basically restricted to the commercially
available chips (or chip sets) which enable a host microcomputer to synthesise
speech. The most common method of synthesising speech today is by the technique known as Linear Predictive Coding (LPC for short). This is basically a memory-compression technique to allow stored speech to be 'played back'. Using this method, about 15 seconds of speech (usually single words) may be stored in a 2K EPROM. The disadvantage of this technique is that although the words are of superb quality, they are 'burned in' - ie. they cannot be altered. You are stuck with the vocabulary you have programmed into your EPROM and a great deal of processing is required on a raw speech input before it can be committed to computer memory in a form suitable for LPC. A typical portable speech development system costs around £8000, effectively putting it beyond the reach of home computer enthusiasts. The raw speech input first has to be digitised. Harmonic analysis is then performed on it and undesirable elements filtered out. Finally the digital information has to be LPC processed and put into the EPROM in a serial form. To overcome this problem, some manufacturers have taken an LPC chip, added some internal ROM, and programmed the chip not with words or phrases, but with allophones. These are fragments of speech which, when run together with other allophones, make intelligible speech. Thus, you are not restricted to your burnt-in vocabulary,
|
but can synthesise any word within the
limits of your 'allophone set' - the
speech sounds you can choose from. For the purposes of this article, we use as an example the General Instruments SP-0256-AL2 chip - an allophone synthesis chip with an allophone set of 64 speech sounds. These 64 sounds may be run together in any combination under the control of a host microcomputer system, for instance the Spectrum. The sounds may be divided into groups which linguists call 'nasals', 'fricatives', 'labials' and so on, but a simpler division into five main groups will suffice: Phonetic sounds These are the simple sounds: a (At), b (Bat), and c (cow); that one may have been taught to read with at primary school. Strong phonetic sounds These are similar in pronunciation to the above sounds but have extra emphasis added for use at the start or end of words. For instance, the 'd' at the start of 'day' is different to the 'd' at the end of 'word' (linguists call these positions word-initial and word-final). Long vowel sounds The 'ay', 'ee', 'eye' and 'oh' sounds. Complex sounds These cover complex, long sounds such as 'th', 'sh', 'uh', and so on. Pauses Pauses of various length which enable sentences to be made. To implement an AL2 system on your Spectrum, first, of course, the chip needs connecting up so that the Z-80A processor in the Spectrum can issue commands and read back status from the chip. The 64 allophones only require a 6-bit address, and to make the chip 'speak' all you have to do is 'present' six bits of data to the correct pins on the chip and drive the 'address load' pin low (logic zero). A convenient way of doing this is to make the AL2 occupy one of the 256 possible 'ports' allowed on the Z-80A. Upon execution of the machine code instruction: OUT a,(PORT), the |
contents of the accumulator are written to
whatever device is occupying the port
location specified by the instruction.
The decoding logic between the processor and speech chip is then enabled
and the data finds its way to the correct
pins on the chip, and further logic drives
the address load pin low. So now the chip is busy speaking an allophone. But suppose you want to output another allophone to make a word. You cannot just go and output another address to the speech chip while it is busy - if you do, the allophone being spoken will be chopped off and the new one started. To guard against this, the AL2 helpfully provides a 'busy' signal on one of its pins, and the Z-80A can read the status of the chip by an IN instruction, and the logical state of one of the data bits in the byte read in will determine whether the chip is busy or not. Alternatively, to make a system with less software overhead, the external logic can allow the Z-80A to output an allophone. But, as soon as it is issued, the Z-80A can be forced into a 'wait' state until the chip is ready again. In this condition, the processor just sits and (effectively) does nothing whilst the chip is busy speaking. The Currah MicroSpeech uses a gate array (a semi-custom chip) to do all these housekeeping tasks without putting the Z-80A into a 'wait' state or slowing down the Basic significantly. Whatever method is used, the speech output from the chip has to be processed and amplified before you can hear it. It comes from the chip in a rather interesting form known as pulse width modulation (PWM for short). This is basically a square wave output which can have a variable mark/space ratio (see Figure 1) and, when 'averaged' by external analogue circuits, a waveform is obtained (Figure 2). The PWM technique generates undesirable 'aliases' (high frequency noise) in the waveform, and the raw wave is processed by filters before being amplified. THE SOFT APPROACHHaving looked at the hardware, now it's time to turn to the software aspects of a speech synthesis system. Obviously it's | |
| highly unsatisfactory to have to keep
outputting raw numbers to the speech
chip - think how much better it would
be if you could just type in letters and
have the software translate them into
allophones for you! Unfortunately, this
is not quite as simple as it appears. Text
To Speech (TTS for short) is an area
under intensive research for incorporation into the so-called Fifth Generation
machines as it includes many features
associated with artificial intelligence. For instance, suppose you wanted to pronounce the word 'female' in a sentence and convert it to the relevant allophone codes for output. The simple program (let's call it Level 1) will scan across the word from initial space to final space and pronounce it phonetically, ie. by considering each letter in isolation. The word would come out rather like 'femalleh'. Another program (let's call it Level 2) will compare the word with a table stored in its memory and pronounce it correctly. The only trouble is that if it cannot find a match for the word under consideration, it will pronounce it phonetically by default. A more advanced program (Level 3) will realise that the 'e' at the end of a word such as this lengthens the initial 'e' to an 'ee' sound, and that the 'a' in the middle is a long 'ay' sound. The word will thus be pronounced correctly. A Level 3 TTS program represents quite a sophisticated processing task, and there are all sorts of horrible anomalies to account for. For instance, how do you deal with 'plough' or 'bough', and yet still get 'trough' right? The problem gets even more severe when the pronunciation of a word depends on its context in a sentence. For instance, take the statement: 'We lead the world in lead pipe manufacture'. Row do you know the correct pronunciation of 'lead'? The Level 4 TTS program incorporates 'context scanning' where the sense of the word is defined by the other words preceding or following it. The human brain can take in this sort of information and pronounce the word correctly because it knows what the sentence means - the computer cannot know the meaning of the sentence (and hence the pronunciation) unless it possesses some degree of artificial intelligence. |
A sensible alternative to the fully
fledged TTS system is to include an
interpreter which will scan a string of
symbols and convert them into allophones (the technique used in the Currah
MicroSpeech unit). The Basic string
variable, S$, is reserved for use by the
system and whenever anything is put
into S$, the interpreter scans the string
and converts the symbols into speech
sounds. The interpreter assumes that
any letter not enclosed in brackets is to
be pronounced phonetically and exceptions are defined as letters enclosed in
brackets. For instance, the strong phonetic 'l' symbolised by (ll) and the long vowel 'o' sound by (oo). Thus 'he(ll)(oo)' is correctly pronounced as 'hello'. The actual choice of symbols used is quite arbitrary; one could equally well set up the standard phonetic symbols (such as the upside-down A and the AE combined) in the user-defined graphics area and use those as the allowed symbols, but this soaks up space which may be required for games. The technique employed in the MicroSpeech unit was to make the symbolisations look how they sound, so that allophone 51 (an 'er' sound) is symbolised by (er) and allophone 5 (an 'oy' sound) is symbolised by (oy). A particularly tricky one was the (dth) allophone. This sounds like the 'th' in 'there' and not like the 'th' in 'think' - the (dth) symbol eventually decided on was the best symbol which was short enough to be easily remembered and yet made sense when written down. The symbols look a little strange on first sight, but once you get used to them they are a lot quicker to program with than by outputting numbers to a port. For instance: (dth)iss iz (ee)z(ee)u (dth)an y(ouu)zi(ng) (aa) p(or)t. You see how you have to think in terms of how the words are spoken rather than how they are written; but this applies equally to a numbers-only system and the symbols are more easily memorised than numbers. And we included a syntax checking program in the on-board software to help users through the initial phases of learning to program in allophone symbols - to give error diagnostics should a mistake be made in syntax. |
A criticism commonly levelled at
allophone synthesis is that, whilst perfectly intelligible, it lacks life and is
rather dull and flat. Intonation is a feature found on some allophone synthesis
systems which helps overcome this disadvantage. You can specify whether
you want an allophone to be raised
slightly in pitch (or even lowered slightly
on some systems) by using intonation
symbols. A common method of doing
this is to use '+' and '-' symbols before
an allophone. The MicroSpeech, with
its two levels of intonation, uses a
slightly different system whereby a
symbol in upper case is intoned up and a
symbol in lower case is left alone. In many ways, allophone synthesis has a lot more going for it than the other methods of speech synthesis, which are basically advanced methods of replaying a pre- recorded signal. But there is definitely room for improvement in the chips currently available, and a 'super- allophone' chip (or chip set) would have such features as 200 allophones to choose from, an 'attributes' port for intonation, volume and pitch of every allophone, and even incorporate some on-board software so that the allophones would run together smoothly with the minimum of software overhead from the host computer. A device like this would enable even the smallest computer to synthesise speech which had both life and character - producing sounds almost indistinguishable from human speech itself. 
Figure 1. A PWM signal. 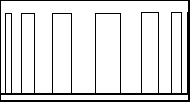
Figure 2. The signal after 'averaging'. |
| TALK TO ME, OH MICROSPEECH | 
| |
|---|---|---|
| One of the great things about speech synthesis add-ons is that, for one reason or another, they usually give your computer an unrivalled capacity to make people laugh. Maggie Burton discovered that Currah Computer Components MicroSpeech turned out to be no exception. | ||
| A MicroSpeech unit is about the size of
two Swan Vesta matchboxes stuck
together by their striking edges, it's matt
black (you have to keep the colour
scheme consistent with Uncle Clive's
tastes) and very light. Actual dimensions are 75 mm wide by 70mm deep by
l7mm high. It clips into the printer/
expansion port at the back of the Spectrum and, of course, it s compatible with
the whole range of extras - printer and
interface et al - so there's no worry
about being unable to list out hard
copies of programs while the MicroSpeech is in use. The unit is made to function by redirection of the sound output to the TV loudspeaker. Instead, the TV lead is plugged into a hole in the MicroSpeech and an output lead from the MicroSpeech then completes the exchange by plugging into the usual TV port. Following switch-on, it isn't long before you notice that every Spectrum key you press is 'voiced' by the computer. The fact that it says 'norrt' rather than 'nought' is just a mere distraction. You can, however, switch these 'key-voices' off by typing LET keys=0; LET keys=1 turns back them on again. Although this could presumably be useful for someone with visual disabilities, one cannot help but envisage problems with the Spectrum's SHIFT keys - which are not voiced. It's also of little help in | editing, so a blind computernik would
still have a lot of problems putting their verbal creations into RAM. Speechfreaks (try getting the device to say that) are likely to be only too well aware of the fiddly nature of many speech synthesis devices. Most of them are better programmed in assembler for full effect; not so with MicroSpeech. It works on the basis of an allophone set rather than the use of smaller phonemes or libraries of words and bits of words. Any contact with addresses/contents of addresses/pushing stacks is reserved for real hackers. In short, machine level work is not necessary. You can make it chat away quite happily from Basic. Each allophone produces a distinct, different sound. The five vowels make the 'school alphabet noises' - Ah, Eh, Ih, Oh and Uh. Combinations of vowels produce different sounds. Single consonants are phonetic. Strong phonetic allophones are double consonants and complex allophones are noises like 'th', 'ch' and 'ear'. They and the strong allophones are enclosed in brackets. The brackets distinguish these sounds from groups of phonetic allophones. Leaving the brackets out of the allophone (ggg) (a strong 'G' as in GOTO) will produce something like 'g-g-g' - a new complaint known as the silicon stammer. Altogether there are 58 allophones and they're designed to cater for every sound in the English language. |
Naturally, heavy compromises are
necessary and, for instance, 'q' and 'x'are not recognised because they can be
made up of combinations of other sounds
- 'kw' for 'qu' and 'ks' for 'x'. Thus, in making up a sentence it is necessary to see the word exactly as it is pronounced, not as it is spelt. Even then it's possible to get the wrong end of the stick -'th', for instance, should be '(dth)'. But there is also a '(th)' - a slightly softer '(dth)'. Knowing which to use is all down to trial and error. Those whose knowledge of Sinclair Basic is reasonable should get to know how the MicroSpeech works pretty quickly. And it's possible to build up libraries of useful phrases by putting them in string variables (from Basic all words to be spoken are treated as strings). You can then use these over and over again, like this: 5 REM OKAY WISEGUY THIS IS IT
Line 40 is the line which does the talking
and S$ is a reserved variable which,
when used, sends all those carefully
planned allophones whizzing off to the
speech buffer. But note that if the MicroSpeech doesn't recognise one part of
|
| a LET S$ statement it'll maintain an
eerie silence or skip that phrase and
jump to the next one it does understand.
Notice the use of the capital 'A' in line
10. Using a capital letter on a vowel
raises the pitch at which that vowel is
pronounced. A limited amount of
intonation is possible in this way - but
beware; one of the best ways of confusing the MicroSpeech is to use a capital
consonant. Even the versatile human
voicebox can do little about raising or
lowering the pitch of the sound 'P' for
instance. Pauses of various kinds can be included with the help of a space, comma, apostrophe or full stop. The apostrophe is useful for giving emphasis to a bit of a word, as in d(oo)n' (tt) - don't - by shoving a discreet and very short pause in where the apostrophe is placed. The space separates words; the comma, phrases; and the full stop separates sentences. A PAUSE command has to be placed between each LET S$ command and the one following. This makes sure the computer can detect each one. If a PAUSE is left out (it need only be PAUSE 1) the S$ command following where the PAUSE should have been (with me so far?) is omitted. One complaint is the amount of interference the MicroSpeech causes on the TV. It makes it more difficult to tune in properly and all the time the machine is switched on, the TV performs its own impersonation of a beehive. | This varies in intensity according to what's on the
screen and is at its worst when a program has been listed. Some of the voicing is very unclear. For instance 'g' and 'd' sound very much the same and there's no real way to get nuances of pronunciation into what the MicroSpeech will say. So don't expect it to read too well from Shakespeare or the Gospel of St John
- although it's been tried, with predictably silly results. Certainly experimentation is necessary to work out some words although the small-but-perfectly- formed manual is fairly helpful in this direction, providing details of how some of the keywords are voiced and giving some pretty stock-in-trade examples. | It's also possible to connect the MicroSpeech to a tape recorder, through a line
lead adjacent to the TV connector.
Using this it's possible to record speech
as it leaves the computer - just plug the
lead into the 'MIC' socket of the tape recorder. And by the same token, output
to a hi-fi is possible by connecting the
same lead to the auxiliary socket of an
amplifier. The speech chip used in the Currah MicroSpeech is General Instruments' SP0256-AL2. Currah and GI worked quite closely together on the project and the end result (at £29.95) is an absorbing, easily used add-on which represents pretty good value in an age of destitution and hardship. It's available, Sinclair-style, by mail order from Currah and comes complete with a demo cassette. It can also be bought through Spectrum Computer centres, Computers For All and Comet. WH Smith and Boots will probably get round to it eventually as well. Several software houses have quickly cottoned on and a good list is available of packages which make interesting use of the MicroSpeech's capabilities. This includes, from Bug-Byte, The Birds and the Bees, from Artic, Talking Chess, and from Romik, a version of 3D Monster Maze. To date, claims Steve Currah of Currah Computer Components, "about 20,000" MicroSpeech units have sold, mainly to stores. No wonder - it's good fun and great value. |
| Home | Contents | KwikPik |