Issue 4, June 1984 - ZIP compiler (part 2 of 4)
| Home | Contents | KwikPik |
| Issue 3 | part 1: "Adding ZIP!" |
| Issue 5 | part 3: "Unzipping ZIP" |
| Issue 6 | part 4: "ZIP to the Stars" |
| Issue 7 | letter: "Unzipping Zapped ZIP" |
| Issue 10 | letter: "ZIPping on a Pension" |
| This program is available on "ZIPi'T'ape", which holds the files for all four parts of the article. | |
The publishers made an awful jumbled mess of printing this article.
The version presented here has been restored to its proper condition.
|
The Basic program for ZIP is listed in this article (Figure 1). It occupies about 16K including variables and REMarks, so it won't fit into a 16K Spectrum (which only allows you about 9K for Basic programs). On a 48K machine, however, you're left with 13K for the program you wish to compile and about 10½K for the compiled machine code. Last month, we listed the instructions which the compiler will recognise, and explained the way ZIP uses memory. This month we'll show how the main program was developed. The whole compiler is written in BASIC, yet it generates programs written entirely in machine-code. Last issue we listed the 'library' of machine-code building blocks. Figure 1 is the program which selects combinations of those blocks which work the same way as the Basic program - except much more quickly! For example, a Basic program to POKE patterns onto the screen will run more than 400 times faster once it has been compiled! THIS WAY UPThe compiler program was developed using a technique called 'top-down design'. The procedure is quite simple and many good programmers use it automatically. Structured programming can be summed up in five words - "think before you write code". There are a number of different techniques of structured programming, but they are all just different ways of helping you get your brain in gear.In top-down design you start by considering the whole problem and working out what you want the design to do. The aim is to break the task down into smaller and smaller steps until you end up with a detailed specification where each step can be converted into a few Basic lines. There's not much point doing this for small projects (except, perhaps, for practice) since you won't need to take many steps before a solution becomes obvious. For larger projects, though, a well-organised approach is very helpful. Top-down design brings two advantages: brevity, since it is easy to spot duplicated problems and use the same code for each instance; and simplicity, since you keep thinking about a problem (in smaller and smaller steps) until the code required becomes obvious. Both advantages make the program easier to understand, which means you can test and alter it easily. If you've ever written a long or complicated program, and then had to produce a succession of different versions, you will probably have noticed that there comes a point when it becomes almost impossible to make further |

Moving on from the specification of his ZIP compiler, Simon Goodwin's back this month with the complete listing of the program along with explanatory notes of how it was written. 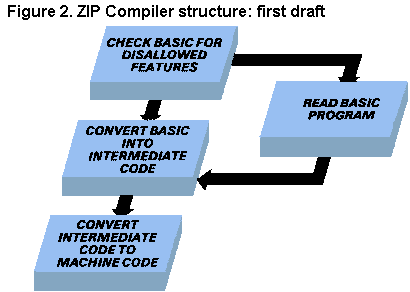
| |
|---|---|---|
|
changes. The whole thing becomes so tangled that it is quicker to re-write it than to alter the old version. The more you think before you program, the less this happens, because you tend to anticipate problems - and work out neat ways around them; you don't end up fiddling with a faulty routine in
memory, trying to salvage bits as best you can. Top-down designs get finished (because you can manoeuvre around problems at the design stage), they do what you intended (because you decided exactly what that was before you started) and they go on working (because you know what |
the effects of changes will be). In general, an hour spent designing saves two hours of testing. And in the extreme case, if you spend too long designing you get bored and never write the program at all, in which case you don't have to test it. (You knew it would work, anyway!). DESIGNING ZIPIn the simplest instance, ZIP is a program which reads Basic and spits out the equivalent in machine code. We'll refine this definition step by step | |

until we can see the structure of the compiler. Basic and machine code are two very different things, so it would be a good idea to use some kind of staging-post between the two - an 'intermediate code', as was discussed last month - translate Basic into intermediate code, then convert intermediate code to machine code. At this point we must consider what we mean by BASIC. We don't mean the entire language as listed in Appendix C of the Spectrum manual, because there's lots of it and many statements (such as the complicated arithmetic functions) would be no better performed in machine code. Therefore, we must choose a subset of Basic with two criteria - usefulness (could programs be written without this feature?) and efficiency (would this feature benefit from compilation?). We end up with the subset listed last month. Don't worry too much about the details because they are not important at this stage. You can add and subtract many features without invalidating the design. The major decisions are to allow whole-number arithmetic, graphics and flow-of-control statements (IF, GO TO, GO SUB, FOR, etc). Now another problem suggests itself - checking that the program to be compiled conforms with our subset. The program can do this as it produces intermediate code, but it's simpler (and therefore probably better) to check for errors in an extra, early, step. In this way we can find errors at the end of a program without having to work out all of the intermediate code up to that point. We now have a three-stage design: check BASIC, convert Basic to intermediate code, convert intermediate code to machine code. Immediately, we spot that there are two steps which read the BASIC. They could share some code. Figure 2 shows the resultant structure, with three main steps and a subsidiary routine shared between the first two. Next we go back to the definition of Basic and think a bit about the second step - converting Basic into machine code. We know the format of each statement: LET statements consist of a variable-name followed by an equals sign then an expression (any arithmetic value or calculation); BORDER statements contain just the keyword followed by an expression; and so on. 'Expressions' crop up over and over again, in POKE, PRINT, IF, RANDOMIZE and other statements. Expressions can be pretty complicated: BORDER ((A>=23)+N(I))/4 AND PEEK(23767)+USR(32000)
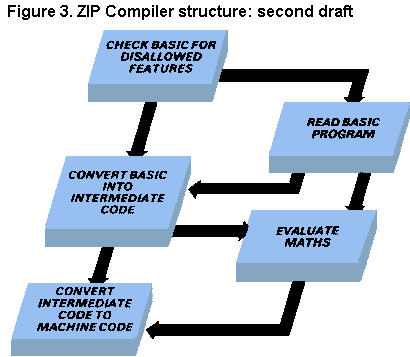
The above would be perfectly legal, although rather unlikely - so it seems a good idea to package that up into a separate routine which the second step can call upon whenever it's needed. The new 'maths' routine will need to have access to |
the Basic program (so that it can scan through expressions) and it will also spit out intermediate codes for each action represented in the expression. Figure 3 shows the resultant structure. We can continue in this way, spotting problems and assigning 'steps' to solve them, until each step seems trivial. Then we write the program. Rather than consume the rest of this magazine with further steps, we've listed the main parts of ZIP in with the listing (see Figure 1). Some of these are common steps which occur in any program - we need an 'initialisation' step to reserve space for variables and code, and a 'main program' step to tie the other sections together. The other three new sections are concerned with manipulating values in memory (DEEK and DOKE, used by the machine-code generator and the Basic reader) and the handling of GO TOs and GO SUBs. Our intermediate code does not contain line-numbers so we must use a separate table of numbers and line positions (memory addresses) to record the destination of each GO TO. (Our intermediate code doesn't use line numbers because we want to be able to jump directly from one line to another, without the need to search for the line required). The only difference between this design and the final program is the fact that Lexical Analysis performs most of the checks which we have assigned to PASS 1. This is done because it turned out to be easier to trap errors as soon as they were found than to pass on messages about them. THE PROGRAM - FINER POINTSWe could probably write a book on the way the ZIP program works - it took four months to write and our notes are about 300 pages long - but the resulting volume would probably be something of a minority interest! The program has been written to be read, with comments in key places and manifest constants whenever possible. The rest of this article explains some of the more devious parts of the listing.It is quite simple to use ZIP without knowing how the compiler works. Load the ZIP program, then type in (or MERGE) the program you wish to compile, making sure that it occupies less than about 13K and uses no line numbers greater than 4999. Type GO TO 5000 to start ZIP. The library is loaded from tape and the compiler starts. If you had already loaded the library you could start ZIP with the command GO TO 5035, or GO TO 5800 if you haven't typed CLEAR since you last used ZIP. The program will scroll up the screen as ZIP checks it for obvious errors. A message appears for each error, immediately after the error has been found. If the entire program is scanned |
without errors, ZIP begins to generate machine-code. The current line number and number of bytes of machine-code produced is shown as compilation takes place. During this second phase more intricate errors may be detected. Once again the line number and a full error message appears, but ZIP skips to the next line of Basic as soon as one of these errors is found in a line. If the compilation takes place without any errors the message "ZIP HAS FINISHED" appears, followed by the command needed to save the entire program - library, variables and code - and the command to RUN the machine code. Normally "RANDOMIZE USR prog" will run the code. (The value of "prog" is shown on the same line, in case you type CLEAR or overwrite the value of "prog". Most of the error messages are self- explanatory; if you are confused, check the specification published last month. A full list of the messages, with explainations, is also contained in the ZIP compiler cassette package. Figure 4 lists the main variables used in ZIP. The program uses a large number of 'manifest constants', which are not listed - these are values which would normally be typed as numbers, but we have written them as variables to make the program more readable. For instance, we use the constant 'CAPITAL Z' instead of 90 (the ASCII code of "Z") and type 'GO TO EXPNEXTS' when we mean get the NEXT S-ymbol in the EXP-ression. HIDDEN NUMBERSZIP takes advantage of the way Basic stores numbers in a program. As well as the individual digits of each number Basic stores an 'invisible' binary copy of each number in a program line. The copy occupies six bytes. In line 5060 we've used variables 'Y' and 'N' instead of the constants '1' and '0', and saved about 500 bytes in the process. This duplication is designed to speed up ZX Basic by removing the need to convert numbers from digits into binary, but in practice it wastes memory to little effect.The first invisible byte is a CHR$ 14 which tells LIST to skip the next five bytes. Then comes the number in binary. Decimal numbers, and very large whole numbers, use all five bytes, but the small integers allowed by ZIP are kept in a compressed form. The ZIP subroutine at line 6110 is used to extract such numbers from a program. The compressed form is marked by a zero byte immediately after the CHR$ 14. If this byte contains any value other than zero, the number is not allowed by ZIP, and an error message is produced. The fourth and fifth bytes contain the number, which can be read using the double-length PEEK subroutine DEEK. Finally the third byte is checked - if it's not zero, the number is negative. |
|
Even binary numbers such as BIN 10101010 are stored in this format, which is why ZIP lists binary numbers in decimal as it checks the program. The only numbers not stored in this way are program line numbers. These are prefixed with CHR$ 13 (enter) and written in reverse order, high byte first. Line 6100 is used to read line numbers. JUMPING AHEADZIP performs GO TO and GO SUB statements at least a thousand times faster than ZX BASIC. ZIP uses direct machine-code jumps, without searching through a table of lines. This means you can't say 'GO TO variable' in a compiled program - ZIP needs to know the destination as the code is generated - but the speed-up is usually well worth-while.In order to compile GO TOs and GO SUBs ZIP must keep a list of line numbers and addresses of the code for each line. This list is kept in a table between TOP and LINETAB, above the compiled program. The variable XREF (cross- reference) indicates the bottom of the table, which slowly fills up as each line is compiled and its address is entered (by subroutine ADDLN). Whenever ZIP finds a GO TO to a previous line, it searches through the table for the line number concerned and extracts the required address. The search is performed by the FIND LINE subroutine, which uses a simple but effective technique called a 'binary chop'. Rather than scan through the list from the start, FIND LINE starts in the middle and compares that entry with the line number required. If the entry is too high, FIND LINE looks at the entry a quarter of the way down, otherwise it looks three- quarters of the way through the list. If the entry there is too low it skips forwards to the midpoint of the last two checks; otherwise it skips back a similar amount. The effect is that the list is cut in half, then half again, and so on until the line (or the nearest subsequent value) is found. This technique can find an entry in a list of 500 lines in just nine steps. FIND LINE copes well with jumps to previous lines, but it can't handle 'forward jumps' - GO TOs and GO SUBs which have not yet been compiled. Another problem involves IF statements. ZIP compiles these using the rule 'IF (expression) is false THEN GO TO (this line +1) ELSE (carry on with this line)'. The effect is that the rest of the line is skipped if the expression fails, which simulates the Basic IF statement, but this also involves a 'forward jump'. How can we generate the GO TO (this line+1) when we've not finished scanning the current line yet, so we've no idea where the next line will start? ZIP solves these problems by deferring them. Since we don't know where the |
destination line is yet, we'll have to put off generating that bit of code until we do. Instead of a line address ZIP puts the number of the line required into the machine code, for the time being. ZIP also makes an entry into a 'line request table' between LINETAB and TP, and then it carries on as if nothing went wrong. The entry is the address at which the dummy line number was stored - the address which must be corrected later. Once the entire program has been scanned the address of every line is known, so FIND LINE always works. A simple routine called PATCH now scans through the line request table. It reads the line-number required from each address to be patched up, and uses FIND LINE to convert the number into a real address. Hey presto! All of the forward jumps are resolved. GUILTY EXPRESSIONSAs we said earlier, mathematical expressions appear all over the place in Spectrum programs. These present special problems when writing a compiler, because the steps involved aren't necessarily performed in the order they are written. For example, think of the statement:PRINT 2+3*4
We can't evaluate the expression 2+3*4 from left to right - otherwise we'd end up with the answer 20 (5*4). If you try this command on the Spectrum you'll get the correct answer 14, because the computer performs multiplications before additions. Chapter 3 of the Spectrum introductory booklet explains this. Basic uses 'algebraic notation', which means that it performs calculations in brackets first, then multiplications and divisions, then addition and subtraction, just as you were taught in school algebra lessons (boo!). The stage at which an |
operator (a sign such as '+' or '*') is performed is called its 'priority'. Multiplication has a higher priority than addition, so '*' is performed before '+'. This problem becomes even more complicated when you remember that expressions can contain brackets, array references (with expressions inside them), functions like PEEK and ATTR, plus variables and numbers. You can even use comparison operators such as ">=", "<>", "OR" or "NOT", and so forth, in Spectrum arithmetic - try 'PRINT 1>2' or 'PRINT 3 AND 2' if you don't believe this. ZIP CALCULATIONSIt takes quite a complicated program to resolve an expression and produce all of the steps - in the right order - to work out the correct value. The section of ZIP between lines 6700 and 6925 is used to evaluate expressions. It was written by the ingenious Jon Smith, who also wrote much of the PASS 2 routine.The expression routine, called 'maths', will handle 27 different operators. The operator '-' appears twice, since it can be used two different ways, as in the expression 'PRINT 2--2'. The first minus is a subtraction sign, the second so-called 'unary' minus marks the second '2' as a negative number. Of course, PRINT 2----2 would be valid too. If you use a whole line of minus signs you clog up the program and receive a "CALCULATION TOO COMPLEX" error, but this should not be a problem in normal use! ZIP re-orders arithmetic expressions into a form of 'Reverse Polish Notation' (RPN) - the calculation sequence used by Hewlett-Packard calculators and Forth programmers. RPN differs from BASIC's 'Algebraic Notation' in that the values to be manipulated always precede the operators. In RPN you write "2 2 +" rather than the familiar "2 + 2". The RPN expression means take two, take two again, then add what you've got. This leaves four - the correct answer. | |||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
The plus operator always adds the last two values together, leaving one value. Multiply, divide and subtract work the same way. PEEK replaces the last value with the contents of the address it specifies. The point is that any expression can be written in RPN and evaluated correctly from left to right, without the need for brackets. "2 + 3 * 4" becomes "2 3 4 * +". The only problem is converting the between the two formats. ZIP scans through an expression, generating instructions to put each number or variable value on a 'stack'. This is a kind of one-ended list - you can put values into the list or take them out, but you can only ever take out the most recently entered value. The effect is rather like pushing oranges into an elastic sock - to get at the first orange pushed in, you must remove all of the subsequent ones, in the opposite order to that in which they were inserted. If you put the numbers '1', '2', '3' and '4' into a stack and then retrieve them one by one, you get '4' back first (the most recently 'pushed' value), then '3', '2' and '1' in descending order. As ZIP stacks up the values in an expression it also makes a stack of the operators, but with one crucial difference - if the previous operator (the one on the stack) had as much or more priority as the operator which has just been found, ZIP immediately generates the code to perform that previous operator and takes it off the stack. This process continues until the operator at the top of the stack has a lower priority than the one which has just been found. Then the new operator is put onto the stack and the scan continues. A special 'end marker' with a very low priority is put on the stack at the start, so that ZIP knows when it has run out of WE'VE GOT IT TAPED!
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
operators. Another 'end marker' is produced at the end of the expression. When the two markers meet we know that the whole expression has been evaluated. If this seems like gibberish, look at Figure 5, which should be worth at least 1e3 words! It shows the process of scanning the expression '2 * 3 + 4 / - 4'. The result, '5', is left on the value stack. Brackets are handled like the END markers, but with a slightly higher priority. The effect is that expressions in brackets are worked out before the operators around them are applied. The open-bracket works as a kind of 'block' on the stack, which only a close-bracket can knock off. Even the brackets of an array subscript can be handled in this way. ZIP uses a special operator 'index' |
to mark the start of a subscript calculation. Examine the expression evaluation routine, using the variable information in Figure 3. The subroutine EXPUSH is used to stack an operator, and EXPOP removes one entry (by moving Z down so that the stack is one unit shorter). One extra quirk is line 7802, which checks for the special case of a lone minus sign before a number. If possible it generates a negative number immediately, rather than the two steps 'stack number' and a 'make last number negative'. 'OH FOR A QL' DEPTThe ZIP compiler is not a perfect example of structured programming: it's been | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
deliberately crammed into 16K of memory (plus the library) and written in BASIC. Squashed as it is, ZIP does work, and it shows that you don't need a disk system or a 'fashionable' language to write a complex, useful software tool. The basic principles of structured design have been followed - it is very doubtful that the program would ever have been finished otherwise! BUGLETSThere's no way to be sure that a compiler is totally 'bug free' - there are just too many possibilities! We've tested ZIP on dozens of programs but we may have missed some flaws. If you find a bug please write to Your Spectrum, stating the exact circumstances in which it occurs (with a listing if possible) and we'll do our best to fix it quickly for you.NEXT MONTH We'll conclude this series with a look at possible enhancements to the compiler. We'll provide subroutines to simulate INKEY$ and RND, plus 'worked examples' showing how you to add high-resolution PLOT and DRAW commands. There'll be a detailed example of the way the machine code templates are fitted together, and an example program to compile which shows just how good ZIP can be! | Here is the ZIP Compiler BASIC listing, or download it as part of the "ZIPi'T'ape" file. | 
|
|---|